Basic Invocation
npm run scrape -- -s <scraper>
This is the simplest version of the script, which runs a single scraper. For example:
npm run scrape -- -s nsf
Currently, this command produces the following output:
$ npm run scrape -- -s nsf
> scraper@2.0.0 scrape
> ts-node -P tsconfig.buildScripts.json scrape.ts "-s" "nsf"
11:19:24 WARN NSF Launching NSF scraper
11:19:41 INFO NSF Wrote 100 listings.
11:19:41 INFO NSF Wrote statistics.
$
You will see that a file called nsf.dev.json has been written to the listings/compsci directory, and a file called (for example) nsf-2021-10-18.dev.json has been written to the statistics/compsci directory.
npm run scrape -- --help
There are many options for customizing the run of a scraper. To see them, invoke help:
npm run scrape -- --help
Here is the output from a recent run. There may be additional options or changes in your version.
$ npm run scrape -- --help
> scraper@2.0.0 scrape
> ts-node -P tsconfig.buildScripts.json scrape.ts "--help"
Usage: scrape [options]
Options:
-s, --scraper <scraper> Specify the scraper. (choices: "angellist", "apple", "cisco", "linkedin", "nsf", "simplyhired",
"test", "ziprecruiter")
-l, --log-level <level> Specify logging level (choices: "trace", "debug", "info", "warn", "error", default: "info")
-d, --discipline <discipline> Specify what types of internships to find (choices: "compsci", "compeng", default: "compsci")
-c, --config-file <config-file> Specify config file name. (default: "config.json")
-nh, --no-headless Disable headless operation (display browser window during execution)
-dt, --devtools Open a devtools window during run. (default: false)
-cf, --commit-files Write listing and statistic files that are not git-ignored. (default: false)
-sm, --slowMo <milliseconds> Pause each puppeteer action by the provided number of milliseconds. (default: "0")
-t, --default-timeout <seconds> Set default timeout in seconds for puppeteer. (default: "0")
-ld, --listing-dir <listingdir> Set the directory to hold listing files. (default: "./listings")
-ml, --minimum-listings <minlistings> Throw error if this number of listings not found. (default: "0")
-sd, --statistics-dir <statisticsdir> Set the directory to hold statistics files. (default: "./statistics")
-vph, --viewport-height <height> Set the viewport height (when browser displayed). (default: "700")
-vpw, --viewport-width <width> Set the viewport width (when browser displayed). (default: "1000")
-h, --help display help for command
You can provide any combination of these parameters, in any order. The only required parameter is the scraper.
Multi-scraper invocation
In the previous version of the scraper, we discovered that puppeteer is not "thread safe", in the sense that running multiple scrapers simultaneously can result in execution errors that do not appear when running each scraper individually.
To avoid this problem, the scrape script supports running of only a single scraper. To support batch execution of multiple scrapers, we have created a Unix shell script (run-scrapers.sh) that invokes the scrape script multiple times, once per scraper. This will isolate each run of the scraper in its own OS process and prevent these sorts of problems from occurring.
The problem with run-scrapers.sh is that it serializes execution, so the overall time to run the scrapers is sum of all individual execution times. A simple way to reduce the overall time is to create one shell per scraper and invoke each scraper in each shell manually. It takes a couple of minutes to set it up, but now the overall time to run all of the scrapers is reduced to the time required to run the slowest scraper. Here's a screenshot illustrating this technique:
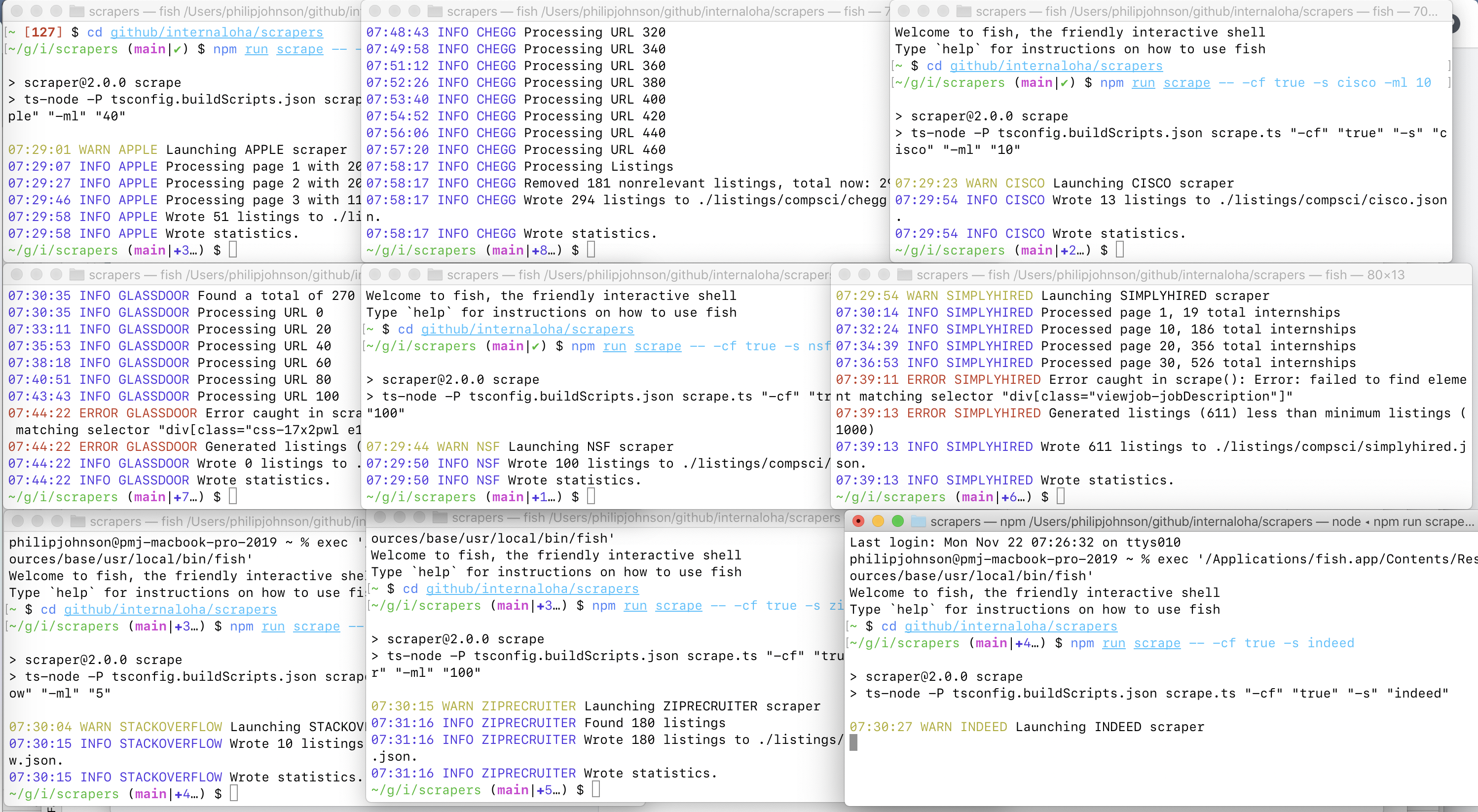
Note that after running the scrapers like this, you must run the statistics script manually to collect the data:
$ npm run statistics -- -cf true
> scraper@2.0.0 statistics
> ts-node -P tsconfig.buildScripts.json statistics.ts "-cf" "true"
Wrote statistics/compsci/statistics.num-listings.csv.
Wrote statistics/compsci/statistics.num-errors.csv.
Wrote statistics/compsci/statistics.elapsed-time.csv.
After that, be sure to commit the listings and statistics files to GitHub.
Example: NSF Scraper
Here is the default run of the NSF scraper. The log level defaults to 'info', so there's very little output.
$ npm run scrape -- -s nsf
> scraper@2.0.0 scrape
> ts-node -P tsconfig.buildScripts.json scrape.ts "-s" "nsf"
12:21:06 WARN NSF Launching NSF scraper
12:21:10 INFO NSF Wrote 100 listings.
12:21:10 INFO NSF Wrote statistics.
Running the scraper with log level 'debug' produces a lot of output, much of which I'll elide:
$ npm run scrape -- -s nsf -l debug
> scraper@2.0.0 scrape /Users/philipjohnson/github/internaloha/internaloha/scrapers-v2
> ts-node -P tsconfig.buildScripts.json main.ts "-s" "nsf" "-l" "debug"
15:45:17 DEBUG root Starting launch
15:45:18 INFO NSF Launching scraper.
15:45:18 DEBUG NSF Starting login
15:45:20 DEBUG NSF Starting generate listings
15:45:22 DEBUG NSF URLS:
https://engineering.asu.edu/sensip/reu-index-html/,https://web.asu.edu/imaging-lyceum/visual-media-reu,http://www.eng.auburn.edu/comp/research/impact/,http://www.eng.auburn
:
:
15:45:22 DEBUG NSF Positions:
Sensor Signal and Information Processing (SenSIP),Computational Imaging and Mixed-Reality for Visual Media Creation and Visualization,Research Experience for Undergraduate on Smart UAVs,REU Site: Parallel and Distributed Computing,Data-driven Security,Undergraduate Research Experiences in Big Data Security and Privacy,
:
:
15:45:22 DEBUG NSF Descriptions:
Research Topics/Keywords: Sensors and signal processing algorithms, sensor design and fabrication, signal processing, wearable and flexible sensors, machine learning, interface circuits, sensors for Internet of Things
:
:
15:45:22 DEBUG NSF Locations:
Tempe, Arizona,Arizona,Auburn, Alabama,Auburn, Alabama,Boise, Idaho,Pomona, California,Pittsburgh, Pennsylvania,Pittsburgh, Pennsylvania,Potsdam, New York
:
15:45:22 DEBUG NSF Starting processListings
15:45:22 DEBUG NSF Starting write listings
15:45:22 INFO NSF Wrote data
15:45:22 DEBUG NSF Starting write statistics
15:45:22 DEBUG NSF Starting close
Multi-discipline support
The scrape script provides a --discipline parameter that defaults to "compsci" but also supports "compeng". The value of this parameter is available to each scraper in a field called "discipline". Each scraper can consult the value of the discipline field and alter their search behavior if they want to implement discipline-specific internship listings.
The discipline parameter also affects where the choice of directory where the listing and statistics files are written. The compsci files are written into listings/compsci and statistics/compsci. The compeng files are written into listings/compeng and statistics/compeng.
At this time, the scrapers do not change their behavior according to the value of the --discipline parameter. So, if you call the scrape script with "--discipline compeng", the only impact will be to write out the listing and statistics files to a different subdirectory.
Generating statistics
Each time you run a scraper, a json file is written to a subdirectory of /statistics containing information about that run. The file name contains the timestamp YYYY-MM-DD, so statistics are only maintained for the last run of the day.
For example, here are the contents of statistics/compsci/nsf-2021-10-08.dev.json:
{
"date": "2021-10-08",
"elapsedTime": 5,
"numErrors": 0,
"numListings": 99,
"scraper": "nsf",
"errorMessages": []
}
You can run the "statistics" script to read all of the files in the statistics directory and generate a set of CSV files that provide historical trends for the scrapers:
$ npm run statistics
> scraper@2.0.0 statistics /Users/philipjohnson/github/internaloha/internaloha/scrapers-v2
> ts-node -P tsconfig.buildScripts.json statistics.ts
Wrote statistics/compsci/statistics.num-listings.dev.csv.
Wrote statistics/compsci/statistics.num-errors.dev.csv.
Wrote statistics/compsci/statistics.elapsed-time.dev.csv.
During development, statistics files are generated with a ".dev.csv" extension. This means you can look at them, but they are not committed to GitHub.
Running the statistics script with the --commit-files flag eliminates the ".dev" suffix component and thus allows the statistics files to be committed to GitHub.
You can browse to those files directory to obtain a usable tabular representation of run data.
Invoke the statistics script with the --help option to see all available options:
$ npm run statistics -- -h
> scraper@2.0.0 statistics
> ts-node -P tsconfig.buildScripts.json statistics.ts "-h"
Usage: statistics [options]
Options:
-l, --log-level <level> Specify logging level (choices: "trace", "debug", "info", "warn", "error", default: "warn")
-d, --discipline <discipline> Specify what types of internships to find (choices: "compsci", "compeng", default: "compsci")
-sd, --statistics-dir <statisticsdir> Set the directory to hold statistics files. (default: "./statistics")
-cf, --commit-files Write listing and statistic files that are not git-ignored. (default: false)
-h, --help display help for command
Development mode
During development, people will be running scrapers and generating both listing and statistics "output" files in their branches. This could lead to lots of spurious merge conflicts when trying to merge your branches back into main.
To avoid this problem, both the scrape and statistics scripts have a flag called "--commit-files" which is (currently) false by default. When false, all listing file names have a ".dev.json" suffix, and all statistics file names have a ".dev.csv" suffix. Both of these suffixes are git-ignored, with the result that all output files you create during development are not committed to your branch or to main.
If you want your data files to be committed, then you just run either script with the option "--commit-files", which makes that flag true. Then the associated output files are created with ".json" (rather than ".dev.json") or ".csv" (rather than ".dev.csv"), and so they will not be git-ignored.